Navigation
Push Cart
Sustains contact-rich cart pushing over a longer forward path.
Accepted to RSS 2026
Abstract
We introduce Ψ₀ (Psi-Zero), an open foundation model to address challenging humanoid loco-manipulation tasks. While existing approaches often attempt to address this fundamental problem by co-training on large and diverse human and humanoid data, we argue that this strategy is suboptimal due to the fundamental kinematic and motion disparities between humans and humanoid robots. Therefore, data efficiency and model performance remain unsatisfactory despite the considerable data volume. To address this challenge, Ψ₀ decouples the learning process to maximize the utility of heterogeneous data sources. Specifically, we propose a staged training paradigm with different learning objectives: first, we autoregressively pre-train a VLM backbone on large-scale egocentric human videos to acquire generalizable visual-action representations; then, we post-train a flow-based action expert on high-quality humanoid robot data to learn precise robot joint control. Our research further identifies a critical yet often overlooked data recipe: in contrast to approaches that scale with noisy Internet clips or heterogeneous cross-embodiment robot datasets, we demonstrate that pre-training on high-quality egocentric human manipulation data followed by post-training on domain-specific real-world humanoid trajectories yields superior performance. Extensive real-world experiments demonstrate that Ψ₀ achieves the best performance using only about 800 hours of human video data and 30 hours of real-world robot data, outperforming baselines pre-trained on more than 10x as much data by over 40% in overall success rate across multiple tasks. We will open-source the entire ecosystem to the community, including a data processing and training pipeline, a humanoid foundation model, and a real-time action inference engine.
Whole-body tasks that combine navigation, pickup, carrying, and placement.
Sustains contact-rich cart pushing over a longer forward path.
Collects a basket, traverses the scene, and finishes with a person-facing handoff.
Maintains stable locomotion while steering a cart through a serving motion.
Transitions from grasp to desk placement without losing the object pose.
Reorients the bottle and pours with controlled wrist motion.
Combined pouring and cart motion in a tighter framing.
Combined pouring and cart motion with a wider whole-body view.
Pulls the tray and completes the disposal sequence in one pass.
Completes a short cabinet-closing action with stable end-effector alignment.
Retrieves a coffee item with careful extraction and handoff.
Combines spraying and contact-rich wiping in a compact routine.
Resets a workspace by cleaning the surface and returning an object to a deliberate final position.
Moves from disposal into floor-cleaning as one continuous household routine.
Executes a compact wrist-driven interaction on a small kitchen control surface.
Coordinates locomotion and sustained pulling force on a larger articulated object.
TWO DATA SOURCES
To maximize the utility of heterogeneous data sources, Ψ₀ decouples the learning process. Human video provides large-scale, high-quality, and diverse manipulation observations, while humanoid data provides domain-specific real-world trajectories for embodied control.

829 hours of human egocentric video capturing diverse dexterous manipulation behaviors. EgoDex provides broad visual-semantic coverage and scalable manipulation priors for long-horizon tasks.

31 hours of humanoid data covering 260 diverse tasks in 7 categories. Humanoid Everyday grounds video priors in whole-body robot actions and embodiment-specific execution.
MODEL ARCHITECTURE
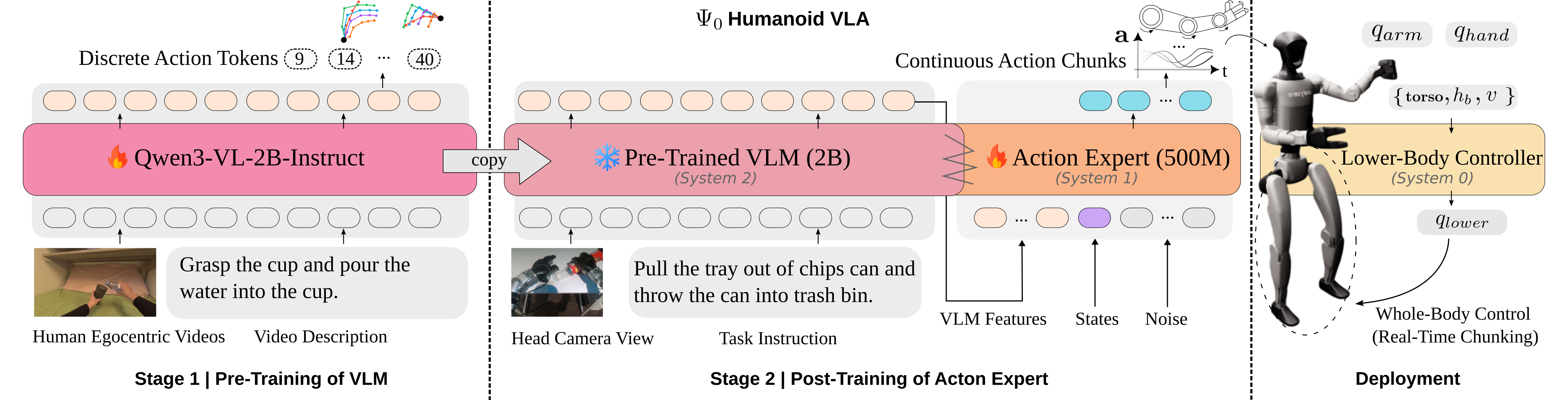
Ψ₀ is a foundation model that adopts a triple-system architecture, following prior work. The high-level policy consists of two end-to-end-trained components: a vision-language backbone (system-2) and a multi-modal diffusion transformer (MM-DiT) action expert (system-1). We use the state-of-the-art vision-language foundation model Qwen3-VL-2B-Instruct as system-2. The action expert is implemented as a flow-based MM-DiT inspired by Stable Diffusion 3, containing approximately 500M parameters. Conditioned on hidden features from the VLM backbone, the action expert predicts future whole-body action chunks. The 8-DoF lower-body actions are passed to system-0, a RL-based tracking policy. We adopt the off-the-shelf controller AMO, which maps these inputs to lower-body joint angles for whole-body control.
STAGED TRAINING
We present an efficient training recipe for learning humanoid loco-manipulation skills from both human videos and real robot data. The overall training procedure consists of three stages: first, pre-training the VLM backbone on large-scale, high-quality, and diverse human egocentric videos while incorporating humanoid data to mitigate the visual gap; second, post-training the flow-based action expert on cross-task real humanoid data; and third, fine-tuning the action expert using a small amount of in-domain task data, which enables rapid adaptation to new tasks.
Training a humanoid foundation model faces a significant data scarcity bottleneck. Therefore, we leverage EgoDex. To further mitigate the visual gap between human videos and robotic observations, we incorporate Humanoid Everyday during this stage.
After the VLM backbone is trained, we freeze its parameters and train the action expert from scratch. We use the Humanoid Everyday dataset for this task-agnostic post-training stage. Conditioned on hidden features from the VLM backbone, the action expert predicts future whole-body action chunks directly in joint space and learns a strong prior for embodied control.
With the pre-trained VLM and the post-trained action expert, our model can be fine-tuned further end-to-end using a small amount of in-domain data and rapidly learn long-horizon, dexterous loco-manipulation tasks.
DATA COLLECTION
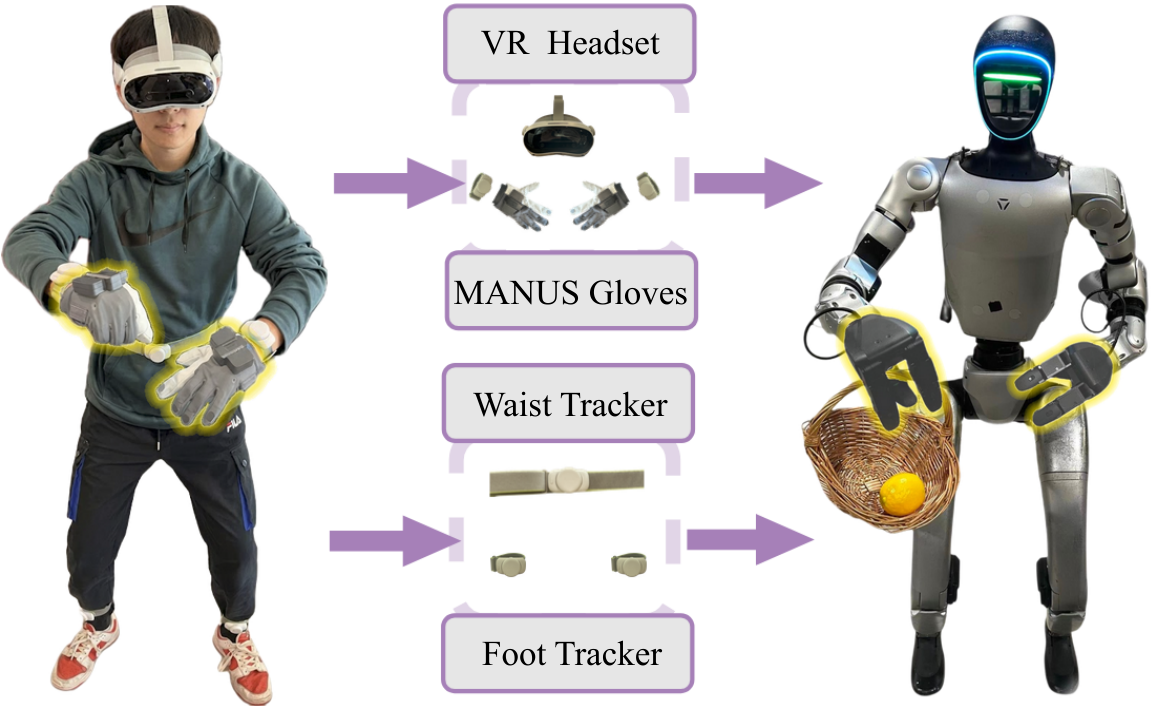
Efficiently learning a long-horizon loco-manipulation task critically depends on the quality of in-domain data for fine-tuning. To address the limitations of prior systems, we propose a tailored teleoperation framework that explicitly separates upper-body pose tracking, dexterous manipulation, and locomotion commands, while enabling single-operator whole-body control. By using a small set of wearable trackers and separating locomotion from in-place whole-body actions, our framework enables single-operator humanoid teleoperation with improved locomotion stability across diverse task scenarios.
DEPLOYMENT
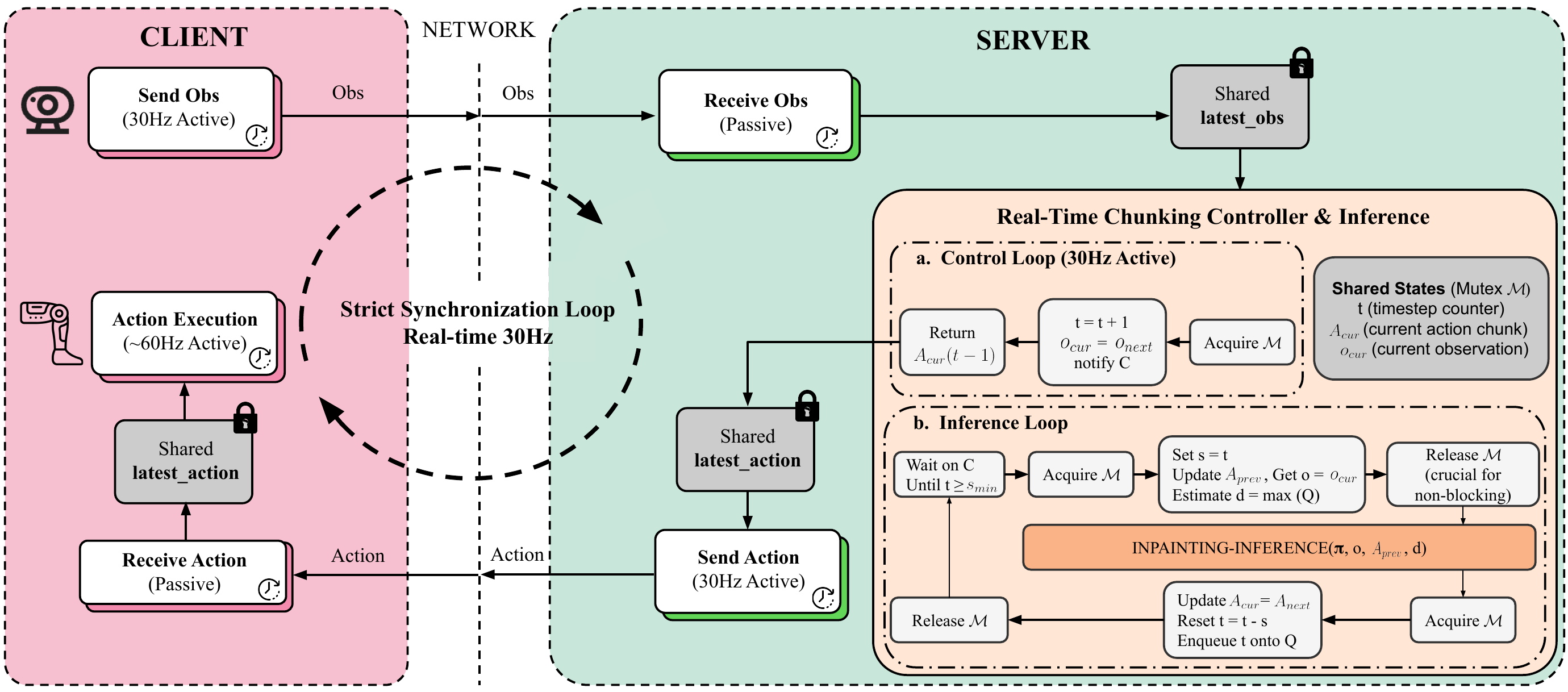
Humanoid robots require smooth and reactive control, particularly when executing long-horizon, dexterous manipulation tasks. However, our model comprises over 2.5 billion parameters, with a single forward pass taking approximately 160 ms. To enable smooth policy rollout despite this latency, we adopt training-time real-time chunking. With RTC, each action prediction is conditioned on the previously committed action chunk and outputs a consistent chunk of future actions, while inference runs asynchronously with execution to avoid interruptions between chunks.
SIMULATION
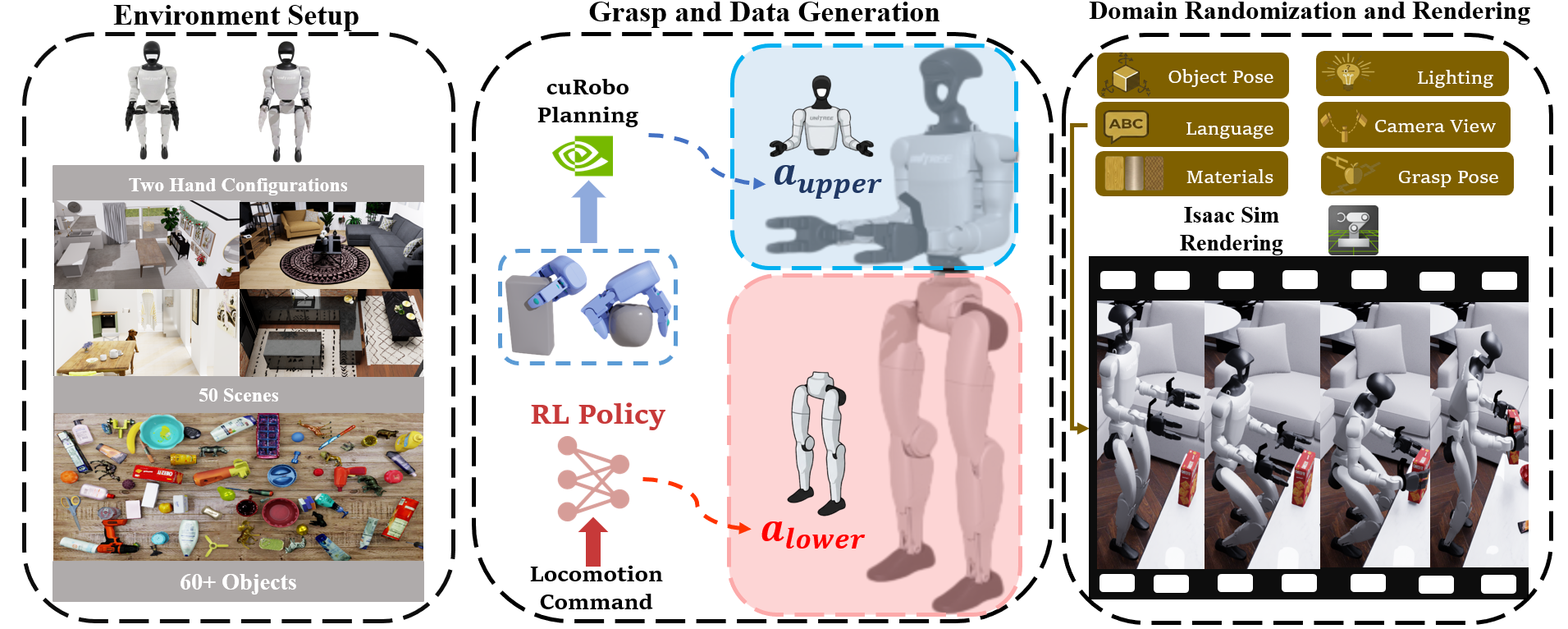
Although our primary goal is to deploy Ψ₀ in the real world, we believe simulation that simulation is very valuable for accelerating experimental iteration and enabling unified, standardized evaluation. We introduce a large-scale humanoid loco-manipulation benchmark in simulation with automated task generation across 50 indoor scenes, imported rigid objects, and randomized episode conditions, giving Ψ₀ a fast evaluation loop before the most expensive hardware experiments.
REAL-WORLD
We evaluate Ψ₀ on eight diverse long-horizon dexterous loco-manipulation tasks involving manipulation, whole-body motion, and locomotion. The tasks range from simple interactions, such as pick-and-place, pushing, and wiping, to more challenging dexterous manipulations requiring precise finger-object coordination, including turning a faucet and pulling out a chip tray.

Real-World Benchmark
As illustrated in the following figure, our model outperforms all baselines by a large margin and exhibits the most stable performance across all eight long-horizon dexterous loco-manipulation tasks. These results highlight the effectiveness of our training paradigm, despite using a relatively small amount of robotic data in both the pre-training and post-training stages.
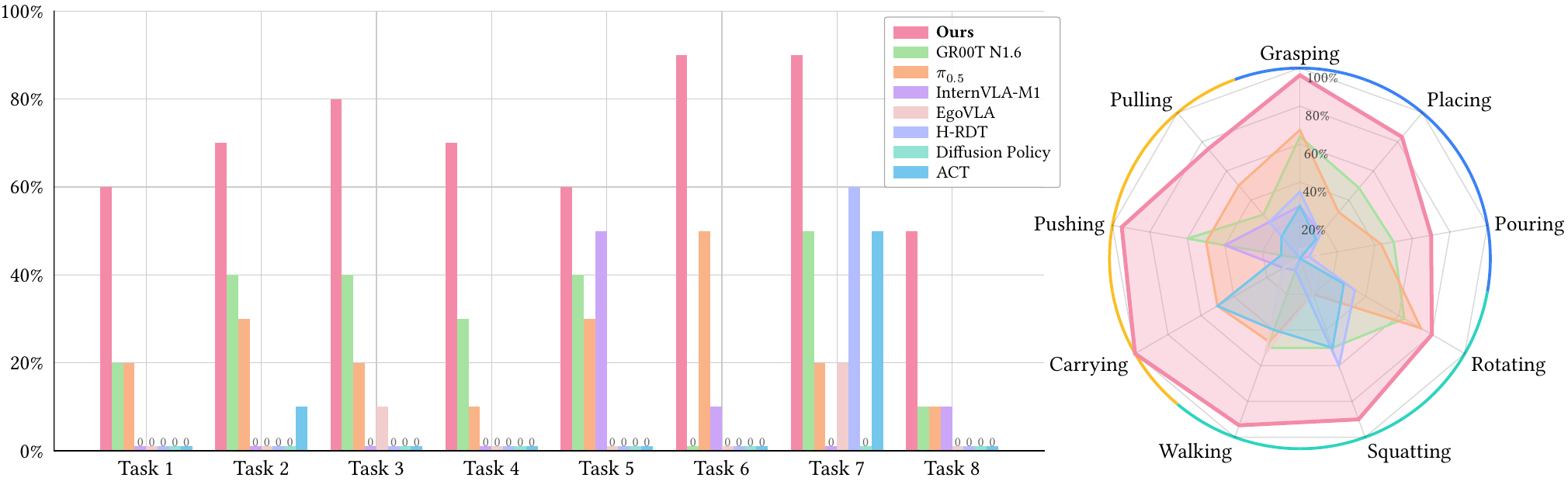
| Descriptions | ACT | Intern-M1 | EgoVLA | H-RDT | Pi0.5 | GR00T N1.6 | Ψ₀ |
|---|---|---|---|---|---|---|---|
| Remove the lid, turn on the faucet, and fill with water | 0/10 | 0/10 | 0/10 | 0/10 | 2/10 | 2/10 | 6/10 |
| Spray the bowl with water, wipe clean, and fold it up | 1/10 | 0/10 | 0/10 | 0/10 | 3/10 | 4/10 | 7/10 |
| Pick the bottle, turn around, and pour into cup | 0/10 | 0/10 | 1/10 | 0/10 | 2/10 | 4/10 | 8/10 |
| Grab the can, turn and pour onto plate, push the cart forward | 0/10 | 0/10 | 0/10 | 0/10 | 1/10 | 3/10 | 7/10 |
| Put the toy into the basket, turn around, and hand it over | 0/10 | 1/10 | 0/10 | 0/10 | 5/10 | 0/10 | 9/10 |
| Push the cart, grab the grapes, and place on the plate | 0/10 | 5/10 | 0/10 | 0/10 | 3/10 | 4/10 | 6/10 |
| Hold the lunch bag and squat down to place on the table | 5/10 | 0/10 | 2/10 | 6/10 | 2/10 | 5/10 | 9/10 |
| Pull out the tray and turn to throw the chip can into the trash | 0/10 | 1/10 | 0/10 | 0/10 | 1/10 | 1/10 | 5/10 |
Ablation Studies
We study the effects of pre-training, post-training, and real-time chunking on a dual-arm long-horizon task which consists of three steps: right-arm pick and place, left-arm pick-and-place and dual-arm lift.
| EgoDex | HE | Post-Training (On HE) | Real-Time Chunking | MM-DiT Action Head | Naive DiT Action Head | Right-Arm Pick-n-Place | Left-Arm Pick-n-Place | Dual-Arm Carry | Overall Success Rate |
|---|---|---|---|---|---|---|---|---|---|
| ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | 1/10 | 1/10 | 1/10 | 0/10 |
| ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | 9/10 | 2/10 | 3/10 | 2/10 |
| ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | 8/10 | 6/10 | 6/10 | 6/10 |
| ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | 8/10 | 8/10 | 9/10 | 8/10 |
| ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | 9/10 | 9/10 | 10/10 | 9/10 |
| ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | 9/10 | 9/10 | 9/10 | 9/10 |
Using only 10% of EgoDex performs worse than the baseline Ψ₀, demonstrating the efficacy of full EgoDex pre-training.
| Setting | Exp. 1 Overall | Exp. 2 Overall |
|---|---|---|
| Baseline (Ψ₀) | 8/10 | 7/10 |
| Variant (10% EgoDex) | 1/10 | 6/10 |
The HE-only variant achieves high performance on tasks that do not require fine-grained manipulation, but still lags behind the baseline on subtasks requiring more precise manipulation.
| Setting | Exp. 1 Overall | Exp. 2 Overall |
|---|---|---|
| Baseline (Ψ₀) | 8/10 | 7/10 |
| Variant (HE) | 4/10 | 4/10 |
We also explore the effect of multi-task fine-tuning and observe that the performance for each individual task drops compared with single-task fine-tuning. We hypothesize that multi-task training disperses the model's learning objective and causes underfitting.
@article{wei2026psi0,
title={{$\Psi_0$}: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation},
author={Wei, Songlin and Jing, Hongyi and Li, Boqian and Zhao, Zhenyu and Mao, Jiageng and Ni, Zhenhao and He, Sicheng and Liu, Jie and Liu, Xiawei and Kang, Kaidi and others},
journal={arXiv preprint arXiv:2603.12263},
year={2026}
}
@article{wei2026simple,
title={SIMPLE: Simulation-Based Policy Learning and Evaluation for Humanoid Loco-manipulation},
author={Wei, Songlin and Ni, Zhenhao and Liu, Jie and Zhao, Zhenyu and Ye, Junjie and Jing, Hongyi and Xia, Junkai and Liu, Xiawei and Leong, Michael and Heng, Liang and Huang, Di and Wang, Yue},
journal={arXiv preprint arXiv:2606.08278},
year={2026}
}